N8N + Supabase Sync for JobAdder Data Integration
In this case study, we’ll share with you how we developed an API-based data syncing system that integrates JobAdder,
Introduction
In this case study, we’ll share with you how we developed an API-based data syncing system that integrates JobAdder, Supabase, and n8n to create a centralized backend for a recruiting firm. The goal was to build a scalable, real-time data infrastructure that could support Bubble.io interfaces and other API-based tools, despite limitations in JobAdder’s native integration capabilities.
Client Background
For this project, our client was a no-code automation consultancy helping mid-market businesses scale through online tools such as Make.com, n8n, and SaaS integrations. Their client, a large recruitment firm, wanted to sync their entire JobAdder database, including over 70,000 candidate records, into Supabase for use as a backend that could power multiple platforms, one of which included Bubble.
Challenge
While working on this project, we faced a number of challenges at different stages of development and integration. These challenges included:
JobAdder lacked event-driven updates, requiring periodic polling.
The system needed to avoid hitting JobAdder’s 2-requests-per-second cap.
Over 90k records across candidates, companies, jobs, and placements.
Data needed to be reshaped and restructured for Supabase + Bubble.
Locations had to be parsed and enriched using Google Places API.
The solution had to be scalable for future AI tools and custom logic.
System Design
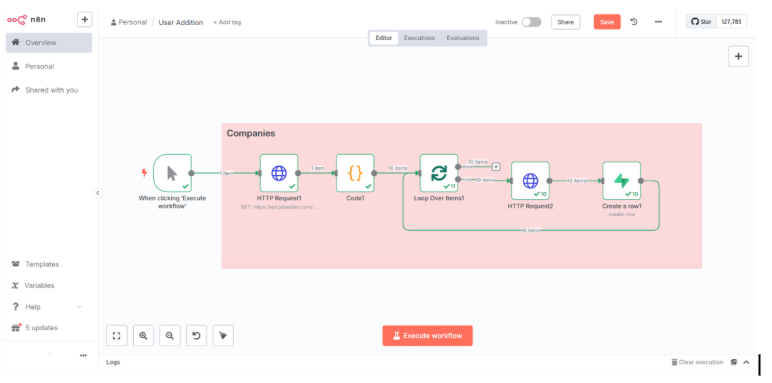
To cater to these challenges, we created the system architecture using three key components that include n8n as the data sync engine, Supabase for the backend database, and Google Places API for address and location handling. Details for how each of these components was used are provided below:
- Built modular workflows to fetch and upsert data from JobAdder every 10–12 minutes.
- Filtered queries to only sync newly updated records using updatedAt logic.
- Created dedicated workflows for Candidates, Companies, Jobs, Submissions, and Placements.
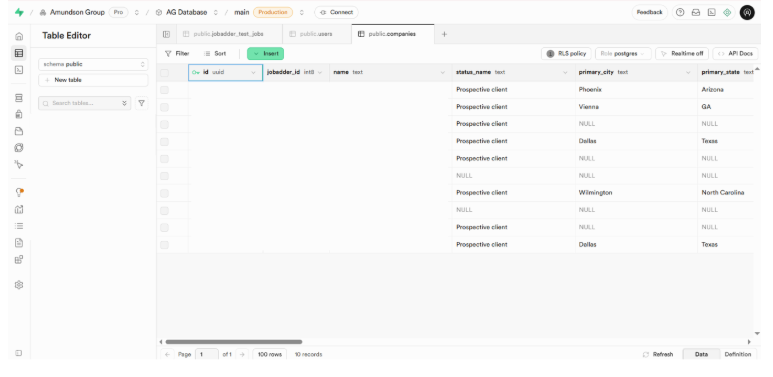
- Designed from scratch to mirror JobAdder data with optimizations for Bubble queries.
- Used object/array fields for flexibility (instead of flat Boolean fields).
- Linked related data types to enable relational queries.
- Created authentication, access policies (RLS), and prepared for Edge Function usage.
- Integrated with Google Places API to parse and format full addresses.
- Cleaned and normalized city data for use in dropdowns and search filters.
- Supported future filtering based on regions, postal codes, or address arrays
Development Process
For this project, we divided the work into three agile phases that included all aspects from the initial setup to the final optimizations. During the setup and schema alignment phase, live APIs were explored, and JSON was clean for object mapping.
After that, we moved on to the workflow automation phase, where we used n8n logic for every object with retries and error logging. Apart from that, we also used the OAuth2.0 setup with JobAdder for secure access.
As far as testing and optimization are concerned, we ensured performance tuning to reduce application programming interface (API) load and finalize syncing logic while validating the data integrity in Supabase.
Launch And Results
After a brief onboarding and Miro-based planning process, the system was deployed with full syncing capabilities in less than three weeks. Some of the key outcomes of the project included:
Records synced in
a clean, normalized
format
Average query
latency for Bubble
frontends
Scalable sync
engine that avoided
API overuse
Extensible database
ready for AI-powered
workflows
Conclusion
This project demonstrates how powerful, well-architected no-code automation can overcome vendor limitations, which leads to new possibilities. Throughout this project, we were able to create a clean and scalable backend that serves as the foundation for real-time recruitment operations and AI-driven interfaces.