BigWolf Ai Audit
Introduction
Client Background
For this project, our client needed a robust, scalable alternative to Stack-AI for document-based compliance audits. One of the primary concerns they shared with us about the alternative option was that it should be able to handle large volumes of files per project stage and return precise and traceable results.
Challenge
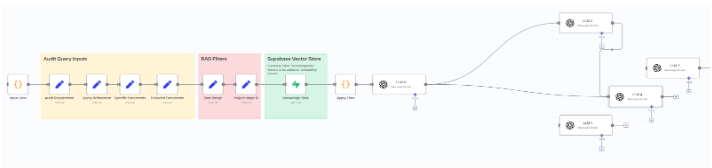
The original solution, built in Stack-AI, used a 5-node LLM pipeline to analyze documents stored in Supabase for 400+ compliance requirements. However, Stack-AI posed several limitations that included:
- Bottlenecks in storage and retrieval.
- Lack of control over model calls and outputs.
- Poor scalability for large document sets
Given the client’s requirements for the project and their business objectives, we decided the goal was to fully replicate this workflow using Supabase, N8N, and direct LLM API access to regain control and improve performance. Some of the key challenges that we faced during the project included:
- Embedding and storing large documents with metadata.
- Enabling filtered queries based on UUIDs for Organization, Project, and Stage.
- Identifying whether compliance requirements were met, using multiple LLM steps
System Design
For this stage of the project, all project documents stored in Supabase Storage were converted into embeddings using OpenAI. Apart from that, we ensured that vectors were inserted into a dedicated Supabase pgvector table with metadata such as file path, project UUID, and stage, and search filtering was enabled based on active/inactive status and UUIDs.
In this stage of the project, the original 5-node Stack-AI pipeline was recreated in N8N using HTTP requests and direct API calls. In addition, we ensured that each LLM node handled a specific task (e.g., requirement match, evidence extraction, probability scoring), and prompt engineering and question refinement were used to tailor queries to each compliance requirement.
For this stage, we ensured that the incoming JSON was triggered via HTTP Webhook. In addition, filtering was handled before initiating the LLM pipeline, and a JSON structure that was returned contained:
- Requirement compliance scores.
- Matching evidence text.
- File paths and document locations.
- Direct links to Supabase-hosted files.
In this stage, we added the output data to Supabase tables for long-term tracking, and a logging system was added to capture the following:
- Run Number.
- User.
- Date/Time.
- Token usage.
- Time to complete.
- Input/Output JSON.
- Status/Error flags.
Development Process
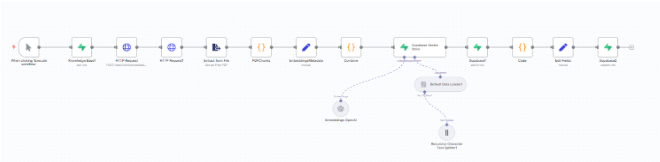
We completed the work in modular phases to allow rapid prototyping and future scalability. For the embedding layer, we batch-processed documents into embeddings and stored them with metadata. After that, we built Supabase queries for fast filtering by project UUID, stage, and activity status.
Once that was complete, we moved onto LLM replication and testing and rebuilt the five LLM stages using OpenAI and Anthropic APIs, used real compliance prompts to test result quality, and calibrated response formatting for consistent JSON output. As for the n8n integration, we created a central cloud workflow (WPF1) to orchestrate the entire process.
In addition, we configured the input via webhook, output to endpoint, and Supabase DB and implemented retries and error-handling within each node. Lastly for user testing we piloted the workflow using actual project UUIDs and document sets, reviewed the JSON output and file traceability with the client, and confirmed accuracy and engagement with the client’s downstream.
Launch And Results
Compliance requirements analyzed per project.
Workflow parity with Stack-AI
Days taken to launch the workflow.